Pacote {{newsatlasbr}}
Para se cadastrar na API, clique aqui. Acesse o GitHub do pacote R aqui.
Introdução ao newsatlasbr
newsatlasbr é um pacote criado para a quarta versão (v.4.0, de 2020) do Atlas da Notícia, com a finalidade de facilitar o acesso aos bancos de dados do Atlas da Notícia por parte de pesquisadores e programadores.
O pacote extrai os dados diretamente da API do projeto, desenvolvida pelo Volt Data Lab.
O desenvolvimento do pacote é do cientista político e analista de dados do Volt Data Lab, Lucas Gelape, com contribuições de Sérgio Spagnuolo e Renata Hirota.
ACESSE O PACOTE TAMBÉM NO GITHUB
Instalar e carregar o pacote
Atualmente, o newsatlasbr pode ser instalado diretamente do seu repositório no GitHub:
if (!require("devtools")) install.packages("devtools")
devtools::install_github("voltdatalab/newsatlasbr")
Uma vez instalado, ele pode ser carregado usando-se a função library.
library(newsatlasbr)
Funções
newsatlasbr possui três grupos de funções:
- Logar na API para obter um token;
- Obter dados agregados de municípios, UFs ou regiões e produzir mapas desses dados;
- Obter dados de veículos de notícia.
Esse tutorial examina esses três grupos.
Observação: alguma familiaridade com uso da linguagem R é recomendada.
LOGAR NA API
Para acessar a API do Atlas da Notícia, os usuários devem ser registrados e inserir o e-mail e senha para autenticação. A função atlas_signin registra essa informação na sessão de R do usuário, para ela ser usada na obtenção do Bearer token de acesso a API.
A função grava o e-mail e senha somente na sessão atual do usuário. Assim, ele deve repetir essa operação a cada nova sessão de R em que ele queira utilizar o pacote. O usuário e senha são pessoais. Então, os usuários devem ser cautelosos ao escrevê-los e salvá-los em scripts, para evitar o seu compartilhamento.
atlas_signin(email = "example@account_exeample.com", password = "pass")
DADOS AGREGADOS DE MUNICÍPIOS/ESTADOS/REGIÕES
Usuários que já exploraram artigos ou reportagens sobre o Atlas da Notícia sabem que os municípios brasileiros são classificados em 3 categorias, segundo o número de veículos de notícias em cada uma delas:
- Desertos de notícia: nenhum veículo;
- Quase desertos: 1 ou 2 veículos;
- Outros: 3 ou mais.
A função get_municipalities combina requisições de API para as três categorias acima para criar um dataset único contendo o número de veículos de notícia em cada município brasileiro (além de incluir outras informações sobre esses municípios). Como ela faz três requisições, a função demora mais a retornar um resultado do que as funções que realizam uma única requisição. Contudo, ela é a única que dá um retrato completo dos 5565 municípios.
As funções a seguir têm uma estrutura semelhante (nenhum argumento) e retorna os seguintes bancos:
news_deserts: municípios que são desertos de notícia;almost_deserts: municipalities that are quase desertos;n_orgs_100k: municípios com, pelo menos, um veículo, informando tanto o número absoluto de veículos quanto a sua taxa por 100 mil habitantes.
all_municipalities <- get_municipalities()
deserts_municipalities <- news_deserts()
almost_deserts_muns <- almost_deserts()
at_least_1_org_muns <- n_orgs_100k()
Essas funções têm “pares”, que permitem a extração de dados agregados em estados/regiões:
news_deserts_state: retorna um banco com o número agregado de desertos de notícias em cada estado ou região. O padrão da função são estados (regions = F);almost_deserts_state: retorna um banco com o número agregado de quase desertos em cada estado ou região. O padrão da função são estados (regions = F);n_orgs_100k_state: retorna um banco com o número absoluto e a taxa por 100 mil habitantes de veículos de notícias nos estados e regiões. Essa função é um pouco diferente das duas anteriores, uma vez que o banco de dados resultante dela sempre terá 27 observações. Seregions = T(que, ao contrário das anteriores, é o padrão da função), novas colunas são adicionadas, incluindo informações sobre a região em que cada estado está localizado.
news_deserts_states <- news_deserts_state()
almost_deserts_regions <- almost_deserts_state(regions = T)
organizations_per_state <- n_orgs_100k_state()
Por fim, newsatlasbr também inclui três funções para gerar e exportar mapas com essas informações, usando dados geográficos do pacote geobr e gráficos do ggplot2 (as legendas dos mapas, porém, estão em inglês):
news_deserts_map: plota um mapa dos desertos de notícia brasileiros. Os dados podem ser agregados em municípios, estados ou regiões (as três funções têm o município como padrão:aggregation = "municipalities"). Para estados e regiões, o usuário deve escolhar se ele deseja visualizar o número absoluto de desertos de notícias (padrão) ou o percentual nessas agregações. Como nas demais funções, o usuário pode exportar os mapas como um arquivo .jpg usando o argumentoexport = T.
# Plotar um mapa com o percentual de desertos de noticia em cada estado brasileiro
news_deserts_map(aggregation = "states", percentage = T)
almost_deserts_map: plota um mapa dos quase desertos de notícia. Os dados podem ser agregados em municípios, estados e regiões. Ao contrário da funçãonews_deserts_map, o usuário só pode escolher o número absoluto dos quase desertos em cada agregação.
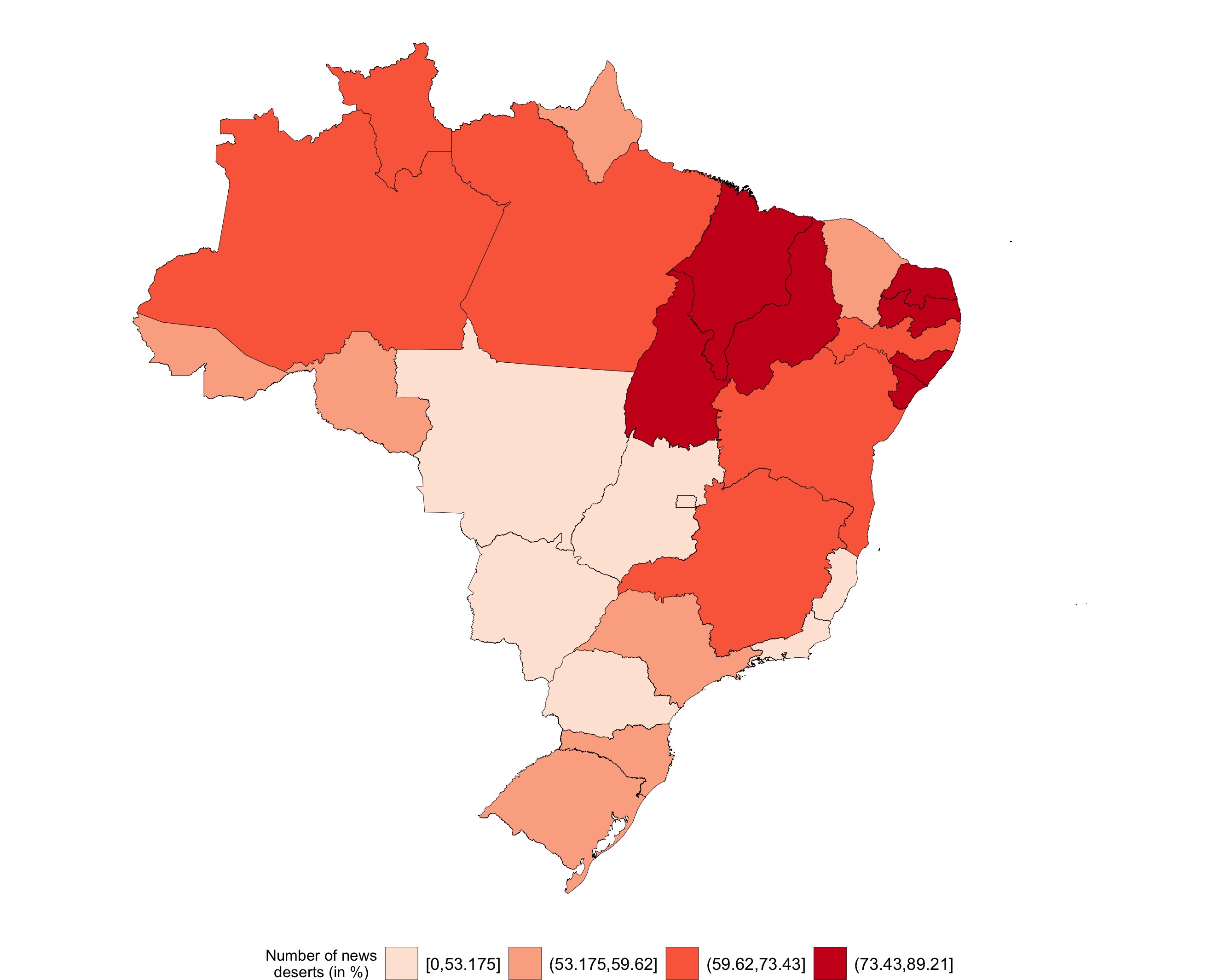
# Plota um mapa de quase desertos em cada regiao do pais
almost_deserts_map(aggregation = "regions")

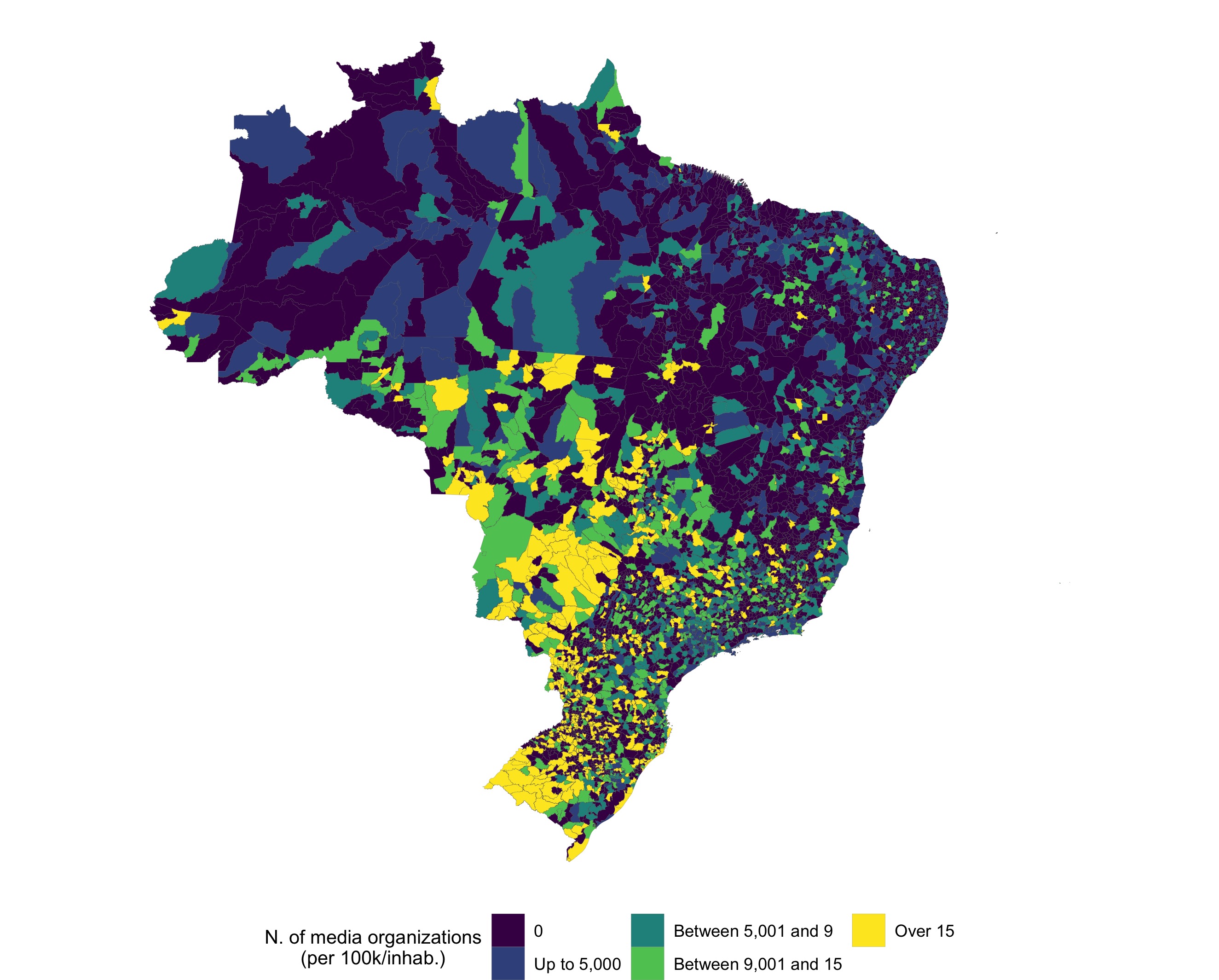
n_orgs_100k_map: plota um mapa com informação sobre o número de veículos por 100 mil habitantes. Os dados podem ser em nível municipal, estadual ou regional.
# Plota um mapa com o numero de organizacoes por 100k/hab em cada municipio
n_orgs_100k_map()
#DADOS SOBRE VEÍCULOS DE NOTÍCIA
Existem duas funções para extrair dados de veículos de notícias brasileiros: organizations_state e organizations_region. Ambas têm uma estrutura semelhante: os argumentos padrão retornam dados de estados/regiões informados (o usuário pode inserir uf = "All" ou region = "All" para obter os dados do país inteiro - esta opção demora mais para retornar os dados, porém); somente veículos de notícia (news = 1) - excluindo, portanto os veículos não-jornalísticos; e todos os tipos de mídia (media = "all").
Portanto, o usuário pode escolher obter dados para o país inteiro, como dito. Ele também pode obter todos os veículos (news = "all"), isto é veículos jornalísticos e não-jornalísticos. Por fim, ele pode restringir os dados a somente um subconjunto de mídias, como “impresso”, “online”, “radio” e “tv”.
# Extrair dados de todos veiculos jornalisticos do estado de SP
sao_paulo_media <- organizations_state(uf = "SP")
# Extrair dados de todos os veiculos jornalisticos do pais
brazil_media <- organizations_state(state = "all")
brazil_media <- organizations_region(region = "all")
# Extrair dados de veiculos impressos em Pernambuco
pernambuco_print <- organizations_state(state = "PE", media = "print")
# Extrair dados de veiculos jornalisticos de TV na regiao Centro-Oeste
cw_tv <- organizations_region("Central-West", media = "tv")